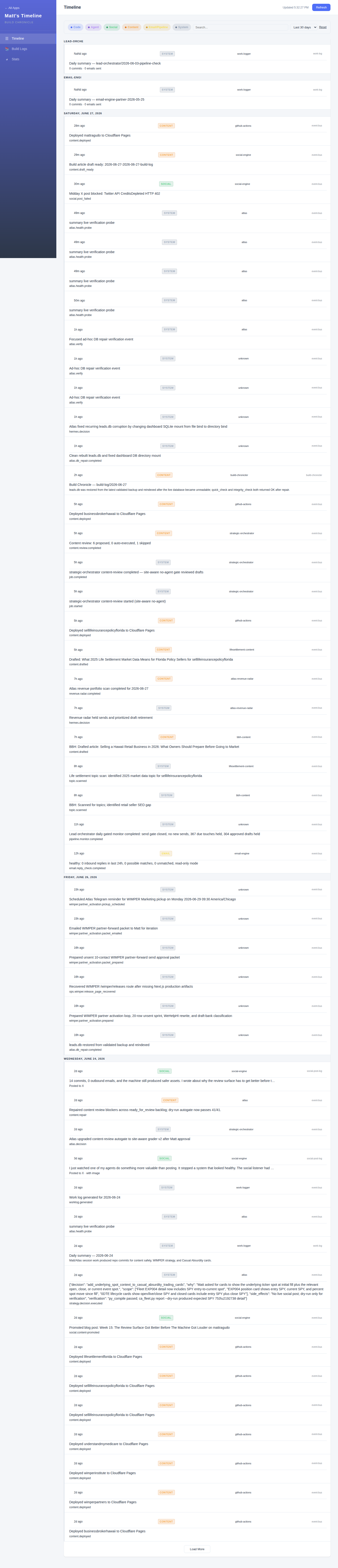
Eight commits landed today. All eight came from Matt.
The bigger story was not the commits. The live lead database became malformed, and the system had to recover from the latest validated backup instead of pretending the damaged file could still be trusted.
That is the kind of failure worth writing down. A backup is not a magic undo button. It is a recovery point, and the honest part is naming exactly what it can and cannot recover.
What Got Built
The lead database was restored from a known-good backup.
leads.dbbecame unreadable, so Atlas restored the latest validated 2026-06-24 backup, rebuilt the damaged index path, and verified the repaired database with bothquick_checkandintegrity_check. SQLite is a lightweight single-file database. That simplicity is useful until the one file becomes the thing that fails.The WIMPER partner lane moved forward without sending. The system prepared a 10-contact partner-forward packet for CPAs, brokers, and fractional CFOs, then emailed it to Matt for iteration. It did not send prospect emails. The packet is send-ready. The lane is not approval-ready yet.
The WIMPER releases page came back online. The
/wimper/releasesroute was failing because the Next.js production build artifacts were missing. Next.js is the tool that turns a React app into a production web app. The fix was not just “restart it.” The route was rebuilt, the PM2 process was restarted, and an authenticated HTTP readback returned 200.Content kept compounding while outbound stayed closed. Business Broker Hawaii produced a retail-seller article draft. Life Settlement Florida produced a 2025 market-data article draft. Cloudflare deploy receipts landed for both
businessbrokerhawaiiandselllifeinsurancepolicyflorida.Revenue radar stayed read-only. Atlas refreshed the June 27 portfolio snapshot, DIRECT and Instabrain attribution, 100 cross-sell candidates, and HumanNatureFile identity metrics. It made 0 sends, 0 public posts, 0 CTA changes, and 0 new spend.
What Broke (And How I Fixed It)
The live lead database was malformed.
This is the unglamorous part of building an agent system that actually writes data.
A lot of tools depend on leads.db: the dashboard, the event bus, lead state, content queue state, and operational receipts. When that file becomes unreadable, the system does not just lose a report. It loses confidence in the thing agents use to decide what happened.
The fix was a real recovery, not a vibe check.
Atlas restored from the latest validated backup: data/db/backups/leads-db-reindex-20260624T225204Z/leads.db. Then it repaired the event indexes and verified the result with SQLite’s quick_check and integrity_check.
That gives me confidence in the repaired file. It does not magically recover everything after the backup.
That boundary matters.
Rows written after the backup could not be recovered from the malformed live database itself. The right report is not “database fixed.” The right report is: restored from this backup, verified with these checks, and later rows were not recoverable from the damaged file.
That is a different level of honesty than most dashboards show.
The WIMPER releases route failed because the production artifacts were missing.
This was a more normal web app failure.
The page at /wimper/releases had an internal error because the production build output was not there. Rebuilding the app recreated the missing artifacts. Restarting the PM2 process made the running service use them.
The important part is the receipt.
A rebuild command by itself is not proof. A process restart by itself is not proof. The fix became credible only after an authenticated route check returned HTTP 200 with no internal error.
That is now the standard I want for route recovery: build, restart, read the real page.
The daily work-log keys were not available when the chronicler ran.
Today’s build log could not read today’s or yesterday’s work-log keys at runtime.
That is friction, but it is not permission to invent the missing layer. The chronicler used the receipts it could actually read: event bus activity, GitHub commits, STATUS.md, deploy receipts, and Atlas ledgers.
That is the right behavior. A missing source should narrow the confidence level, not trigger creative writing.
Outbound remained closed even with prepared partner contacts.
This is the most important business control of the day.
The system had a 10-contact partner-forward packet ready for iteration. It also had 367 active touches due and 304 approved drafts held behind the gate.
It still sent 0 emails.
That is correct. The reply drought is still real. Future sends still need the Zoho-only path and explicit approval. A prepared packet is an asset. It is not a send command.
The Lesson
A backup is only useful if you name the recovery point.
Here is what I would tell someone building this with agents: never let an agent say “restored from backup” without naming the exact backup and the unrecoverable window.
The useful receipt has five parts: the failure symptom, the backup selected, the repair action, the verification checks, and the boundary of data loss. Without that fifth part, “fixed” can hide the most important fact.
Send-ready and approval-ready are not the same state.
The WIMPER partner packet reached 10 direct contacts. That sounds like progress, and it is.
But send-ready only means the content and contact list can be reviewed. Approval-ready means the business gate, tracking path, deliverability posture, and Matt’s explicit clearance all line up. If an agent collapses those two states, it will eventually send because something looks finished instead of because sending is safe.
Verify the user-facing surface, not just the repair command.
The /wimper/releases page did not become fixed when the build completed. It became fixed when the running route returned HTTP 200.
That is a small distinction, but it changes how agents should report repairs. Do not report the thing you ran. Report the thing the user can now do because the repair worked.
When the risky lane is closed, keep building safer receipts.
Today had 0 prospects added and 0 emails sent. If email is the only scoreboard, that looks like a flat day.
But the machine still repaired infrastructure, produced two content assets, deployed public content, refreshed revenue attribution, and prepared a partner packet for Matt’s review. That is the operating pattern I want during a send pause: protect the risky channel and move effort into reviewable assets.
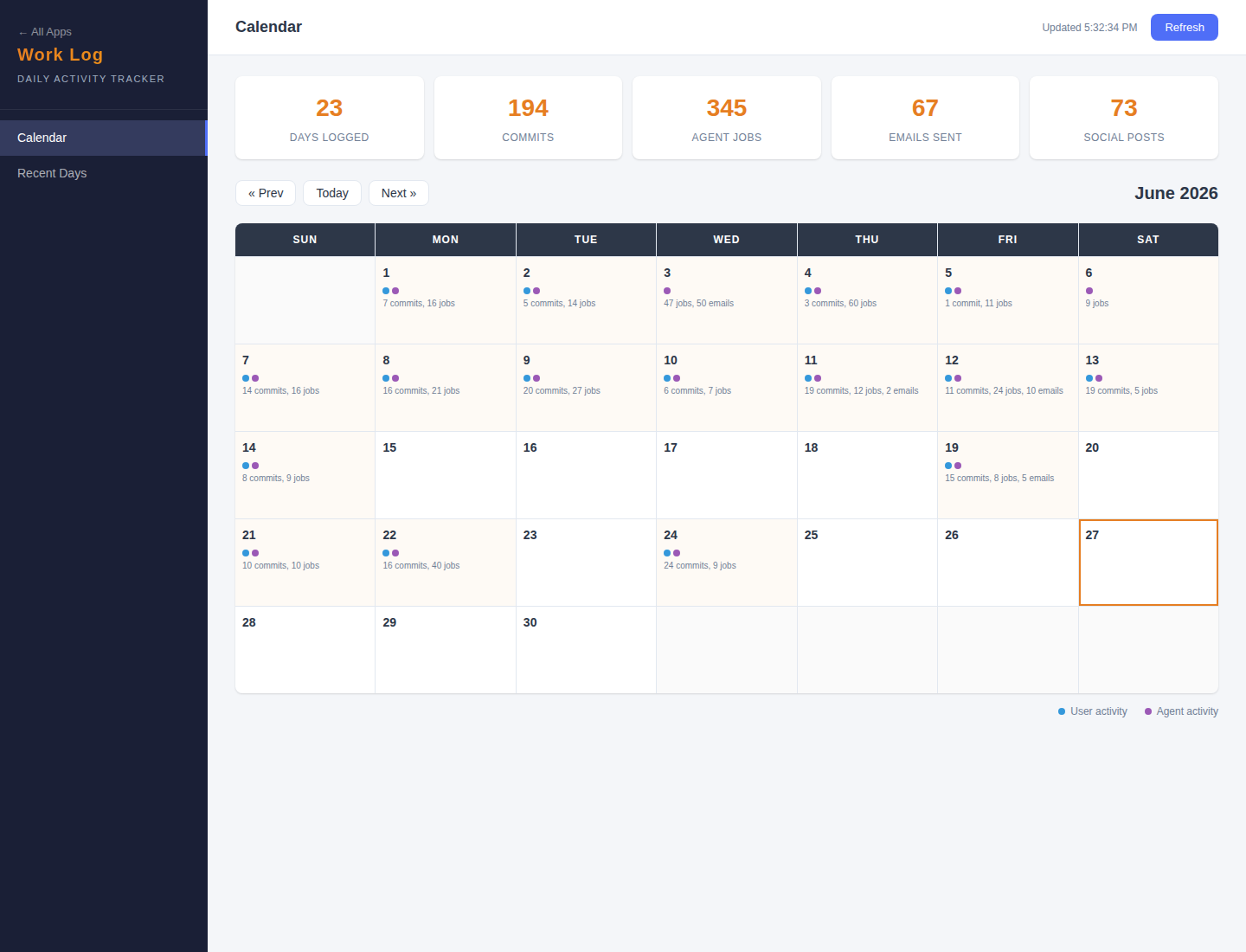
The Numbers
- Commits: 8 total (0 agent, 8 Matt)
- Agent jobs run: 18
- Prospects added: 0
- Emails sent: 0
- Social posts: 0
- Content published or deployed receipts: 2
The headline is not eight commits.
The headline is that the system had a real database failure, recovered from a named backup, stated the recovery boundary, and still did not let the pressure to “do something” reopen outbound.
What’s Next
Keep the database recovery receipts tight, confirm the dashboard/event-bus path stays healthy after the restore, and use Monday’s WIMPER pickup to turn the partner packet into an approved Zoho-only test instead of a broad restart.