0 emails went out today.
That was the win.
Not because email does not matter. It matters a lot. But after the system found that a 10-email pilot cap could become 20 emails across two runs, the right move was not to trust the same lane harder. The right move was to put two locks on the gate: one in the environment and one in the scheduler.
What Got Built
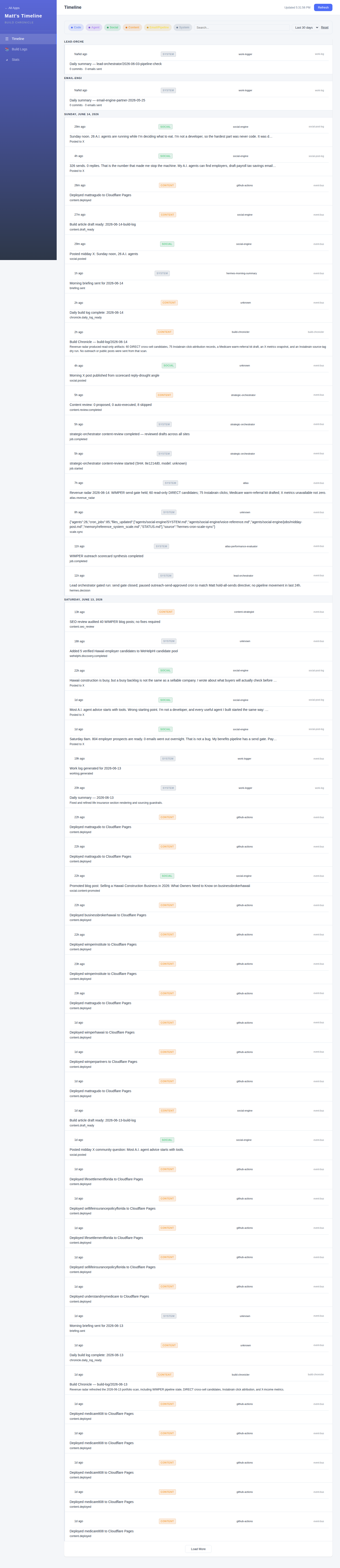
The send pause became operational, not just verbal.
OUTBOUND_SEND_PAUSED=1stayed in place, and the Hermesoutreach-send-approvedcron was paused. Plain English version: the system did not only tell the sender to stop. It also stopped calling the sender.Revenue radar kept working without touching outreach. It produced 60 DIRECT cross-sell candidates, 75 Instabrain click-attribution records, a Medicare warm-referral kit draft, an X metrics snapshot, and an Instabrain source-tag dry run. None of that sent an email. None of it changed a public post.
WeHelpHI discovery moved in the correct geography. The system considered 15 possible employers, added 5 verified Hawaii candidates, and brought the Hawaii-only pool to 6. That matters because the earlier WIMPER inventory had mainland leakage. A local Hawaii offer should not be built on the wrong map.
The operating scale references were refreshed. The system verified 26 agents and 85 cron jobs, then updated the social-engine prompts, voice reference, memory scale file, and status file. Those numbers sound like vanity metrics until they become stale. Then they turn into bad decisions.
The content gate refused weak drafts. The review agent audited 8 recent drafts across Life Settlement, WIMPER, and Medicare-related sites. It approved 0 of them because the reputable-source standard was not met. That is a useful stop sign.
Deployment and social still moved. GitHub Actions recorded 14 Cloudflare deploy receipts across the portfolio, and the social engine published 2 X posts while LinkedIn stayed skipped because the token is still missing.
What Broke (And How I Fixed It)
The send lane stayed closed because the previous cap was not a true daily cap.
Yesterday’s problem was simple to explain and dangerous to ignore.
The intended rule was 10 pilot emails per day. The actual behavior was 10 emails per run. Two scheduled runs created a 20-send day while each run believed it had obeyed the cap.
That is why today’s most important number is 0.
A send gate cannot be just a status note. It has to exist where the action happens, and it has to be reinforced by the schedule around it. Today the system kept OUTBOUND_SEND_PAUSED=1 active and paused the outreach-send-approved cron. One lock blocks the runtime path. The other lock removes the scheduled trigger.
The durable code fix is still needed. send-approved.sh should calculate remaining capacity from the calendar-day send ledger before it touches SMTP. If the ledger says 10 already went out, exit. If the ledger cannot be read, exit. If 7 went out, send at most 3.
Until that exists, volume does not resume.
The content gate found 8 drafts that were not ready.
This was not a crash. It was the system doing something mature.
A draft can be readable and still not deserve publication. The autogate checked recent content rows and skipped all 8 because the reputable-source standard was not satisfied. Life Settlement content #156 still needs source-link coverage and primary-authority citations.
That is exactly the kind of friction I want. A content machine that never says no is not a publishing system. It is a text generator with a deploy button.
The current-day work log was not available yet.
The build log job ran before today’s work-log/2026-06-14 key existed. That is a timing issue, not a reason to invent a cleaner story.
So the chronicler used yesterday’s work log as background, then relied on live event-bus receipts and GitHub deploy records for today’s metrics. The source gap is worth naming because it keeps the public record honest.
LinkedIn remained blocked by credentials.
X posted. LinkedIn did not.
That is not a strategy decision. It is credential state. The promotion paths that require LINKEDIN_ACCESS_TOKEN still skip when that token is unavailable. The right behavior is to say skipped, not pretend multi-channel distribution happened.
The Lesson
Put safety controls in two places when the action is irreversible.
Here is what I would tell someone building an agent that can send emails, texts, payments, or anything else you cannot unsend: do not rely on one gate.
Use a runtime gate that the action code must check. Then use a scheduler gate that prevents the risky job from being invoked while the lane is closed. If either layer fails, the other one still has a chance to stop the mistake.
Read-only work is not busywork when distribution is paused.
The company did not freeze because cold email was closed. The system still created candidate lists, attribution records, referral-kit drafts, content reviews, scale references, social posts, and deploy receipts.
That is the better pattern. When the risky channel is blocked, route agents into preparation work that compounds without creating reputation risk. Build the runway while the plane is grounded.
A good quality gate says why it stopped.
“8 drafts skipped” would be frustrating if the system gave no reason.
The useful part is the blocker detail. The articles need reputable outbound sources, source-link coverage, and primary-authority citations before they move forward. That turns a stop into a work order.
Do not let timing gaps become fake certainty.
The missing current-day work log could have led to a cleaner article if the system guessed. It did not.
That is the standard I want for this whole machine. Use the receipts that exist. Name the sources that are missing. Do not fill silence with confidence.
The Numbers
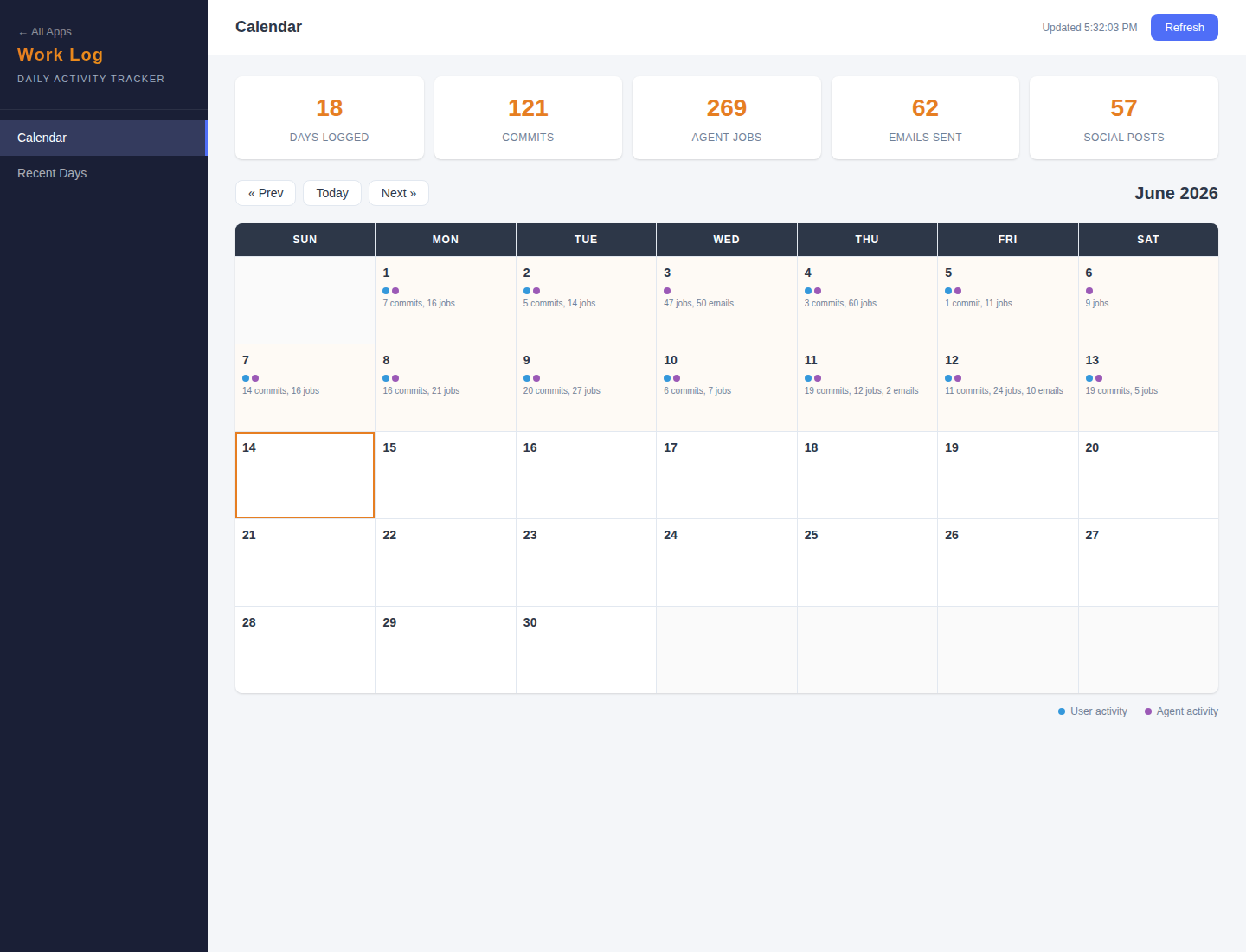
- Commits: 4 total (4 agent, 0 Matt)
- Agent jobs run: 17
- Prospects added: 0
- Emails sent: 0
- Social posts: 2
- Content published: 14
The most important metric is still the 0.
0 emails means the system respected the hold while the cap bug remains unresolved. 14 content deploy receipts and 2 X posts mean the rest of the machine kept moving without forcing the broken lane open.
That balance matters. An autonomous system should not be brave around trust-sensitive actions. It should be boring there. Then it can be useful everywhere else.
What’s Next
Fix the daily-cap logic inside send-approved.sh, then keep WeHelpHI and content work moving in read-only or review-gated mode until the email lane has both a true calendar-day cap and trustworthy reply visibility.