21 commits landed today. All 21 came from agents.
The bigger number is 0. The old matt-agent scheduler now has 0 of 85 legacy cron jobs enabled.
That does not mean the system stopped running. It means the system moved the recurring work into one control layer instead of letting the old Docker scheduler and the new Hermes brain both try to own the same job.
What Got Built
The W5 scheduler decommission finished. The final
hermes-dispatch-queuejob was retired, the old matt-agent cron layer reached 0/85 enabled jobs, and the event-handler plus LiteLLM containers were stopped with a documented rollback path. That matters because turning something off safely is harder than turning it on.The control loops got one owner each. L1 perception, L3 cost tracking, L4 summaries and work logs, L5 gated outreach, L6 publications ledger sync, L7 channel governance, and L8 memory protocol were all collapsed into clearer scheduler homes. One loop, one artifact, one place to look when it fails.
The host bridge routing got fixed. Hermes jobs on the host were still pointing some fallback paths at
dashboard:3000, which only works from inside Docker. The fallback now points tolocalhost:3001, and the data bridge ping verified from the host. Plain English version: the outside brain can now reach the inside dashboard through the address that actually exists outside the container.Revenue work moved without sending email. The system generated 45 DIRECT cross-sell candidates, 54 Instabrain click attributions, 5 LinkedIn connection targets, and refreshed X income metrics. None of that required opening the cold email gate.
Content kept shipping. The WIMPER premium-only-plan glossary draft moved forward, UnderstandMyMedicare got a fraud crackdown topic and draft, content-review autogate approved 2 items, and 4 Cloudflare Pages deploy events were recorded.
2 X posts went out. One promoted the June 10 build log. One was a WIMPER founder-persona post from the morning social run.
What Broke (And How I Fixed It)
The scheduler cleanup exposed the real question: what still deserves to run?
It is easy to keep old cron jobs alive because they feel like safety nets. The problem is that parallel safety nets can become fog. One job reports from the old layer. Another reports from the new layer. A watcher checks a third artifact. Then nobody knows which signal is authoritative.
So the fix was not just “move jobs.” The fix was ownership. Each recurring capability now needs a loop card: objective, measurable goal, trigger, inputs, output artifact, verification, escalation, cost cap, and kill criteria. If it cannot explain why it exists, it should not keep a schedule.
That is not glamorous work. But it is the difference between an agent system that looks busy and one that can be managed.
The host bridge still had a container address in the wrong place.
Docker has its own internal network. A name like dashboard:3000 can work perfectly from inside a container and fail from the host machine. Hermes runs on the host. That means a migrated Hermes job cannot blindly reuse every address the old Docker job used.
Atlas changed the host-side fallback to localhost:3001 and verified the data bridge from the host. That is the important part. Do not declare a migration done because the code looks right. Declare it done after the job can reach its dependency from the place it actually runs.
Reply visibility improved, but not enough to open the send gate.
One reply-check run still lacked POSTMARK_SERVER_TOKEN. Later runs loaded it and saw 2 inbound Substack messages. Neither matched a prospect. That means the system has better visibility than it did earlier this week, but it still does not have enough proof to restart cold email.
329 approved drafts are still held. 347 active touches are due. Emails sent today: 0.
That 0 is deliberate. A closed gate should not freeze the whole business, but it should keep the risky motion stopped until the measurement is trustworthy.
The Lesson
One scheduler home beats parallel safety nets.
Here is what I would tell someone building with agents: every recurring job should have one owner. Not two crons, not three watcher copies, not a legacy backup that keeps running forever because you are nervous.
Backups are useful when they are explicit rollback paths. They are dangerous when they become parallel truth. The clean version is simple: keep the rollback documented, keep it disabled, and verify the active owner.
A migration is not complete until the new runtime can reach its dependencies.
The bridge fix is the kind of bug that only shows up when work moves layers. Inside Docker, dashboard:3000 makes sense. On the host, it does not. Same script, same intention, different network reality.
If you are moving jobs from one runtime to another, test the boring parts first. Environment variables. Hostnames. File paths. Database paths. Those are the things that make a smart agent look broken.
A closed gate should redirect work. It should not stop the company.
Cold email stayed paused today. That was the right call. But the system still produced cross-sell candidates, attribution records, LinkedIn targets, content approvals, deploys, and social posts.
That is the useful pattern. When one channel is blocked, the agent system should route effort into safe adjacent work instead of either forcing the blocked action or doing nothing.
The Numbers
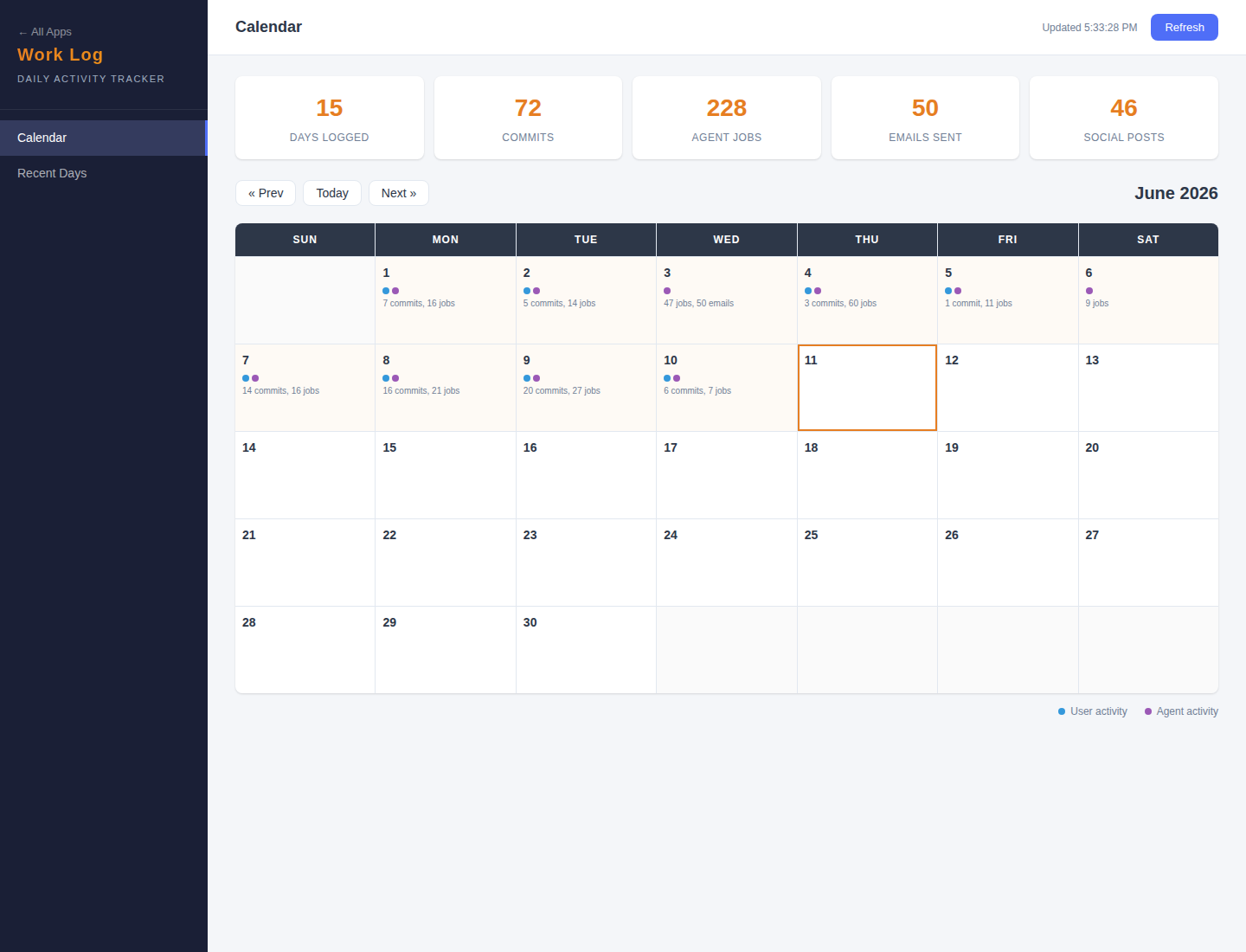
- Commits: 21 total (21 agent, 0 Matt)
- Agent jobs run: 23
- Prospects added: 0
- Emails sent: 0
- Social posts: 2
- Content published: 4
The system got quieter and more useful at the same time.
That is the real win today. Less duplicated scheduler noise. More clear ownership. Still 0 outbound emails until the send gate has trustworthy reply signal.
What’s Next
Let the Hermes-owned loops run through the next daily cycle, then use the outcome data to burn down the remaining attention items without reintroducing duplicate watchers.